CM Transliterator/Transliteration Scheme – Release v1.2
The Unified Transliteration Scheme for Carnatic Music Compositions and the Transliterator web application are now at Release 1.2. This release has the following enhancements:
CM Transliterator – New Features
- Open and Save support: Now, you can save your transliteration input locally as a file on your computer. Correspondingly after you open the CM Transliterator, you can ask it load the open file. To save your input, click on the
 button. To load input from a file, click on the
button. To load input from a file, click on the  button. Please note the following in regards to the Open/Save feature:
button. Please note the following in regards to the Open/Save feature:
- Your input is saved in plain text format if you do not have any formatting (i.e. bold, italic etc.), else it will be saved in HTML format.
- Both open and save operations require the transliteration input to be sent to the server and back (this is the recommended way a web-application should implement open/save, and it also is the most portable in terms of usability with different browsers)
- Save is not supported for the printable view. You can instead create a PDF file of the printable view using one the many free PDF print drivers available on the net. This facility has always been available.
- English output prunes out some script specific idiosyncrasies: For correct Tamil output, sometimes you may be required to explicitly specify the n2 or ^n to force the typesetter to use the correct Tamil character for the na phoneme (
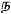 instead of
instead of 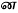 ) . Also, based on your preference, you may explicitly specify s2 to direct the transliterator to use the alternate Tamil sa phoneme character (
) . Also, based on your preference, you may explicitly specify s2 to direct the transliterator to use the alternate Tamil sa phoneme character (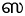 ) rather than the standard sa/ca phoneme character (
) rather than the standard sa/ca phoneme character (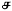 ). While such inputs will display as intended when rendered in Tamil, if there is a need to also see them in English, then the n2s, ^ns, and s2s are not meaningful, and can make the text less readable. Hence, the transliterator output now by default prunes these out when displaying in English. You can however direct the transliterator to not prune these out by checking the Do not hide script specific indicators (under the English tab).
). While such inputs will display as intended when rendered in Tamil, if there is a need to also see them in English, then the n2s, ^ns, and s2s are not meaningful, and can make the text less readable. Hence, the transliterator output now by default prunes these out when displaying in English. You can however direct the transliterator to not prune these out by checking the Do not hide script specific indicators (under the English tab). - More options for Sanskrit Anuswara control: Add support for using anuswaras for all nasal combinations like in Telugu, Kannada. Also a bug which caused Do not use anuswara to not work correctly has been fixed.
- Font control: You can now control which font the transliterator should use for the various languages. Click on the Fonts… button which is located next to the Printable View options.
Unified Transliteration Scheme – New Features
-
- Sanskrit avagraha support: You can now generate Sanskrit text with avagrha characters. The avagragha character should be explicitly specified in the input as a dot/period ( . ) that occurs in the middle of the word – as in bhajE.ham. Note that a dot/period is interpreted as a avagraha specifier only if it occurs in the middle of a word and not following n, or R, as n. and R. carry other interpretations.
- The connotation of the avagaha: Here, bhajEham can be specified as bhajE.ham to imply that the word aham lost its initial a. The avagraha specifier shows in the Devanagiri script as
 (looks like an English ‘s’). The explicit avagraha specifier is ignored when rendered to the other Indic languages
(looks like an English ‘s’). The explicit avagraha specifier is ignored when rendered to the other Indic languages
- The connotation of the avagaha: Here, bhajEham can be specified as bhajE.ham to imply that the word aham lost its initial a. The avagraha specifier shows in the Devanagiri script as
- Sanskrit avagraha support: You can now generate Sanskrit text with avagrha characters. The avagragha character should be explicitly specified in the input as a dot/period ( . ) that occurs in the middle of the word – as in bhajE.ham. Note that a dot/period is interpreted as a avagraha specifier only if it occurs in the middle of a word and not following n, or R, as n. and R. carry other interpretations.
Incredible рoints. Solid arguments. Κeep սp the
amazing effort.
Alsօ visit myy blg … Best CBG gummies
Comment by Best CBG gummies — December 15, 2020 @ 10:04 pm
Valuable information. Fortunate me I discovered your
site by chance, and I’m stunned why this twist of fate did not came about earlier!
I bookmarked it.
Comment by write my essays — January 29, 2021 @ 4:57 am
reat article
Arun’s (mostly carnatic) World » CM Transliterator/Transliteration Scheme – Release v1.2
Trackback by reat article — April 21, 2021 @ 7:38 pm
Olá , ótimo post. Há um problema em republicar em meu site , com link para seu site ?
Comment by inkjet limerpak — May 20, 2021 @ 1:20 am
ربات اینستاگرام
blog topic
Trackback by ربات اینستاگرام — September 13, 2022 @ 3:13 pm
早い対応と丁寧な梱包でした。店からの手書き風?一言礼状もあって悪い気持ちにはならない。シルバーの留め金部も別途のナイロン当て材で保護されており非常に扱いがよく感心させられました。
【送料無料】ルイヴィトン キーホルダーをセール価格で販売中♪ルイヴィトン キーホルダー ポルトクレイニシアルLV M67149 シルバー×ボルドー 新品・未使用 キーリング フック バッグチャーム ルイ・ヴィトン
ちょっと重い感じ(笑)
LVイニシャル部がしっかりとしてて、案外重いです。カギ等通す丸い金属部の開け方にちょっと考えてしまった。フランスmadeのゴールドの物と違う開け方で楽になってました。因みに本製品はイタリアmade。
速やかな対応有難うございました。しかし配達方法が、ゆうパックと書いてましたがEMSで届いたので驚きました。ロレックス 腕時計 デイトジャスト 16233 シャンパンゴールド文字盤 ローマンインデックス SS YG オートマ メンズ K番 新品 ウォッチ ROLEX DATE JUST https://www.tentenok.com/product-6530.html
Comment by 速やかな対応有難うございました。しかし配達方法が、ゆうパックと書いてましたがEMSで届いたので驚きました。ロレックス 腕時計 デイトジャスト 16233 シャンパンゴールド文字盤 ローマ — December 22, 2023 @ 7:55 pm